What does this scrapper do?
Before renewal of the SEC website, there was another scrapper to build dataset. Now, since the website is renewed completely, the past scrapper won’t work. Thus, this new web scrapper is created to address the changes. Please refer to the guide below.
Download
Dependency: Beautifulsoup4, Pandas,requests.
Download: Link
Description
Before the renewal of the website, there were no matchings between proposed and final rules. Thus, we had to match each propose and final rule based on RIN after scrapping both propose and final rule. However, the website contains rule matchings based on RIN. To address possible changes of the website, this scrapper is designed to scrap all it can scrap, rather choosing certain parts. Since the scrapper takes all possible information, it is crude without being refined. Information refinement will be done at next step.
Sample & Guide
Following examples are executed on google colab
1.
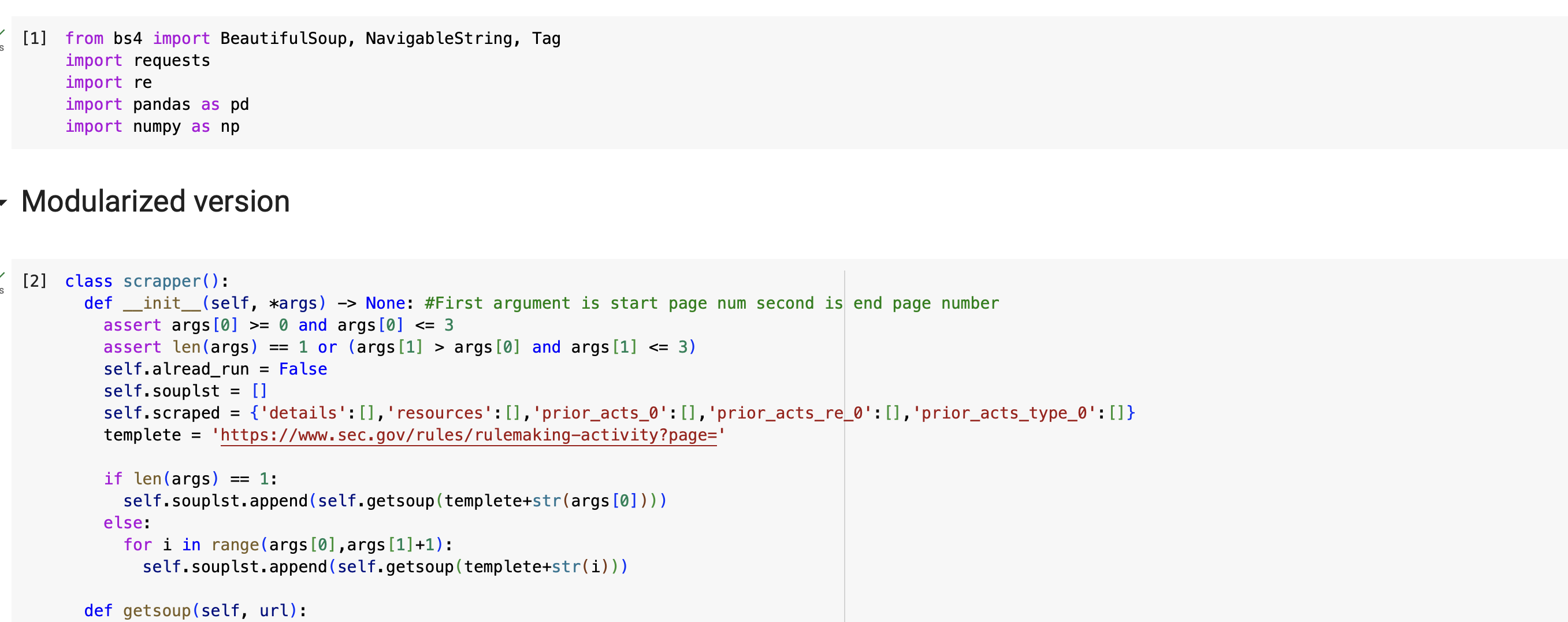
The scrapper has two parts. One is modularized, and the other is non-modularized. In this guide, we will use modularized part, because it’s made for quick and easy use for everyone.
If you want to learn about scrapper or customize it, feel free to use non-modularized part.
The image here shows you modularized part of this scrapper. Run this part before start.
2.
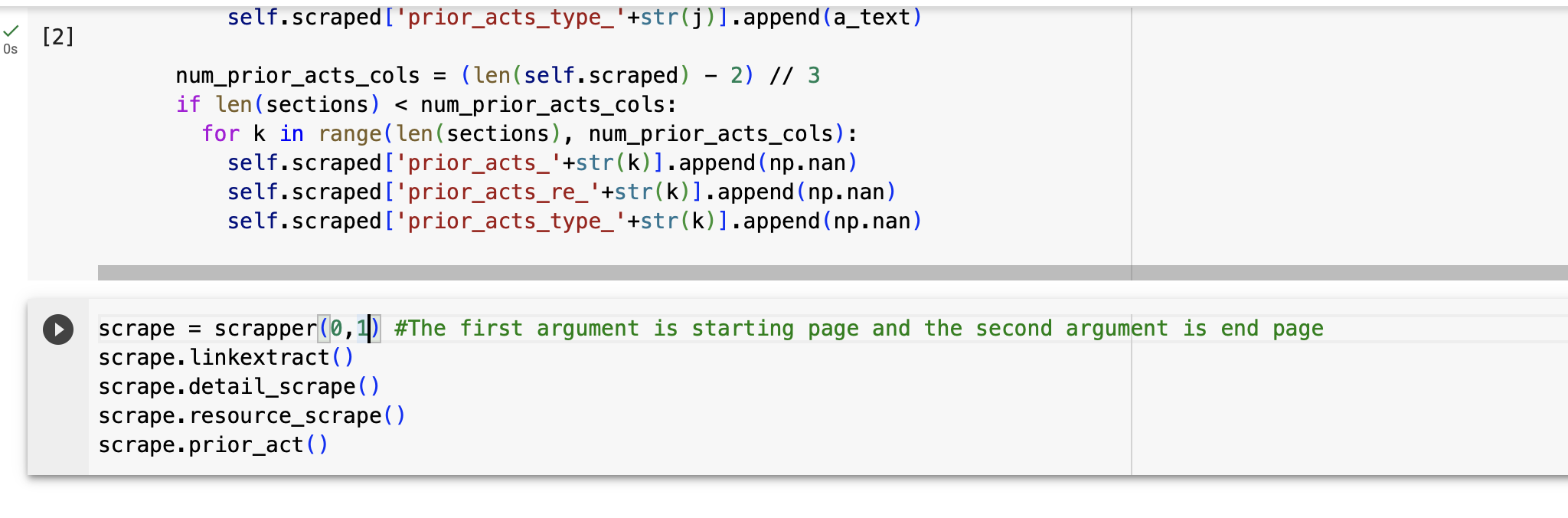
All you have to do with this step is choose the range of pages you want to scrape. For the being time(Sep, 2, 2023), the SEC website has four pages. Thus, the maximum range will be 0 to 3(starts from 0). In this image, the range is set up from 0 to 1. Once you set the range of your own, run this part. It will take 5 to 20 mins depending on the range you chose.
3.

Once the previous part is done, please run this code to creat csv file.